Liza Shulyayeva & Olabisi Oduola

Imagine being able to reduce your costs in AWS Lambda by 40% without writing any code. It's truly amazing, right? Let's take a closer look.
The lambda function we're working with is responsible for handling and processing a huge amount of data collected from partners worldwide. It deals with around 410 million records every day.
AWS Lambda is a service provided by Amazon Web Services that allows you to run code without worrying about servers. It's a convenient solution because it takes care of availability and scalability for you. It also integrates well with other AWS products like SQS, SNS, Kinesis, and API Gateway. Plus, it offers easy-to-use logging features through AWS CloudWatch. The best part is that it usually costs less than other options because you only pay for the time your code runs.
The pricing for AWS Lambda is straightforward. It's based on the amount of memory you choose for your function and how long it runs. More memory means more cost but also faster execution time. Sometimes, it can be cheaper to use more memory, especially for applications that require a lot of processing power, like calculating prime numbers.
Let's take a look at an example to understand the costs. We'll consider a function that calculates prime numbers and run it 1000 times. Depending on the memory levels you choose, the function may take different durations to complete.
Now, let's explore some Lambda configurations that can help reduce costs in our case:
-
Runtime Architecture: This option allows you to choose the type of computer processor used by Lambda to run your function. The current choices are ARM64 and X86_64.
-
Memory: This setting determines the amount of memory available for your Lambda function when it's invoked.
-
Timeout: This setting determines how long an invocation can last.
AWS Kinesis is a service that simplifies the collection, processing, and analysis of real-time streaming data. It offers cost-effective ways to handle streaming data at any scale and allows you to choose the best tools for your application.
Integrating Kinesis Data Streams with Lambda is a straightforward task, whether you use the web UI or CLI. The CLI command "AWS lambda create-event-source-mapping" helps you add Kinesis as an event source for your Lambda function.
While it's easy to add Kinesis to Lambda, understanding certain configurations and their impact on cost and performance can be challenging. Let's take a look at some important configurations:
-
Batch Size: This determines the number of records pulled from your stream or queue and sent to your function in each batch. Small batch sizes can increase ingestion time, while large batch sizes can unexpectedly increase execution time and cost.
-
Maximum Retry Attempts: This setting determines the number of retries before discarding records. The default is infinite, which means your Lambda function can get stuck processing the same batch if there's an error, leading to increased costs. It's essential to set a proper timeout for your Lambda function.
-
Parallelization Factor: This setting determines the number of batches processed concurrently from each shard. Increasing this factor can help if your Lambda function can't keep up with the load from Kinesis. However, be cautious because it's a trade-off between queue time and cost.
-
Maximum Batching Window in Seconds: This sets the maximum time Lambda waits to gather records before invoking the function. It affects the trade-off between queue time and cost. Even if you set a batch size of 1000, Lambda invocations may be less than that because Kinesis triggers the function as soon as records are written to the stream.
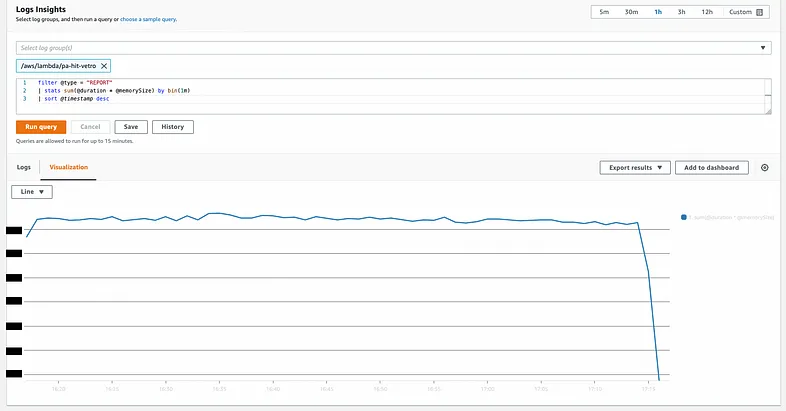
To optimize costs in Lambda, we followed empirical methods and made incremental changes to settings to observe their impact on costs and performance. We used AWS CloudWatch Insight query to monitor the relative cost changes over time. It helped us track the changes between different iterations and adjust accordingly.
In the pricing table for AWS Lambda computing power, you may have noticed that we didn't mention CPUs. That's because in AWS Lambda, you can only configure the memory, and more memory means more CPUs. Increasing the memory capacity leads to higher costs but faster execution time. Since you're charged based on a combination of both factors, it can be cost-effective to use more memory, especially for applications that require a lot of processing power, like calculating prime numbers.
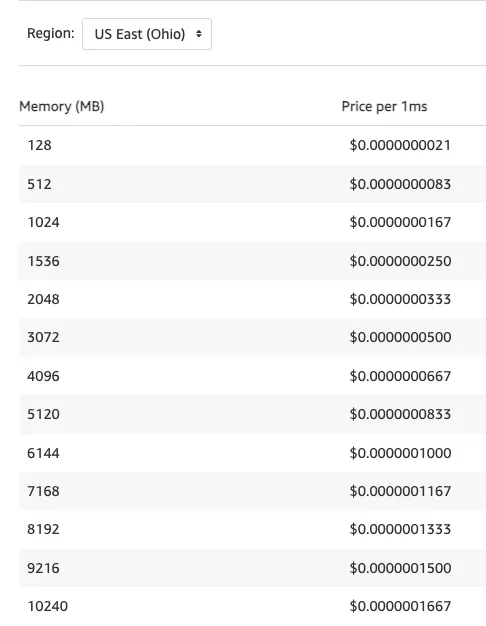
Let's take a look at an example to understand the costs. Imagine running a function that computes prime numbers 1000 times. The average durations for different memory levels are shown in the table.
Now, let's explore some Lambda configurations that can help reduce costs:
-
Runtime Architecture: This setting allows you to choose the type of computer processor used by Lambda to run your function. The available options are ARM64 and X86_64.
-
Memory: This setting determines the amount of memory allocated to your Lambda function during invocation.
-
Timeout: This setting determines the maximum duration of an invocation.
AWS Kinesis is a service provided by Amazon that simplifies the collection, processing, and analysis of real-time streaming data. It offers cost-effective ways to handle streaming data at any scale and gives you the flexibility to choose the tools that best suit your application's requirements.
Integrating Kinesis Data Streams with Lambda is a straightforward task that can be done using the web UI or CLI. Here's how you can add Kinesis to your Lambda function using the CLI command "AWS lambda create-event-source-mapping."
While adding Kinesis to Lambda is easy, understanding some of the configurations and their impact on cost and performance can be challenging. Let's take a look at some important configurations:
-
Batch Size: This determines the maximum number of records pulled from your stream or queue and sent to your function in each batch. Small batch sizes can increase ingestion time, while large batch sizes can lead to higher-than-expected costs due to increased execution time.
-
Maximum Retry Attempts: This setting determines the number of retries before discarding records. The default setting is infinite, which means your Lambda function may get stuck processing the same batch if there's an error. This can significantly increase costs, especially if you haven't set a proper timeout for your function.
-
Parallelization Factor: This setting determines the number of batches processed concurrently from each shard. Increasing this factor can help if your Lambda function can't keep up with the load from Kinesis. However, it's important to consider the trade-off between queue time and cost.
-
Maximum Batching Window in Seconds: This sets the maximum time Lambda waits for records before invoking the function. It determines the trade-off between queue time and cost. Even if you set a batch size of 1000, Lambda invocations may be less than 1000 because Kinesis triggers the function as soon as records are written to the stream.
Cost Optimization on Lambda:
We were able to reduce our costs by 40% through empirical methods and incremental changes in settings. We experimented with different configurations to see how they affected costs and performance. We used an AWS CloudWatch Insight query to monitor the relative cost changes over time. While it didn't give us the actual cost, it helped us compare the changes between different iterations.
Here are the steps we followed:
-
Creating a staging Lambda: We set up a separate Lambda function that was identical to our production one but didn't have write access and wouldn't affect our production environment.
-
Connecting Production Kinesis: We used our production Kinesis service with this Lambda function. We made sure we stayed within the data limits of Kinesis since we knew we were well below them.
-
Taking Baseline Measurements: It was important to establish a baseline measurement before optimization to have a sense of direction for the process.
-
Empirical Testing: We systematically changed settings, recorded the results, and monitored the cost graph mentioned earlier. Based on the graph, we further adjusted the changed values to maximize cost reduction. Instead of testing every possible combination of settings, which would have been time-consuming and less cost-effective, we took a greedy approach and focused on changing one setting at a time.
-
Risk and Impact Analysis: After obtaining the test results, we sorted the configurations from cheapest to most expensive. We considered system delays that aligned with our SLAs (Service Level Agreements) and evaluated possible risks associated with the new settings before coming to a conclusion.
Winning Configurations:
-
Memory: We kept the memory unchanged as higher memory configurations offered little benefit and posed higher risks. Doubling the memory provided slightly faster performance but also doubled the cost for each millisecond of invocation, which could result in unexpected costs.
-
Batch Size: We found that the batch size didn't significantly affect performance or costs unless it fell below or exceeded certain thresholds.
-
Parallelization Factor: We changed the parallelization factor from 3 to 2. While this caused a small delay in queue ingestion, it was at a manageable level and improved overall queue ingestion time by around 10 times.
-
Maximum Batching Window in Seconds: We changed the maximum batching window from 0 to 3 seconds. Despite having a large amount of data to ingest, the parallel invocations of our Lambda function allowed us to set a 1-second batching window without significant delays. This change resulted in significant cost reduction.
-
Runtime Architecture: We switched from X86_64 to ARM64 architecture. Although we didn't see a noticeable performance increase for our case, AWS charges 25% less for ARM64 architecture. By incorporating this change, we achieved approximately 16% cost reduction. Taking into account the 25% reduction specifically attributed to the runtime architecture change, the overall cost reduction reached 40%, and the remarkable thing is that we achieved this without changing the code at all. Welcome to the era of cloud computing!
Effects of Optimization:
As a result of our optimization efforts, we successfully reduced costs by 40%.
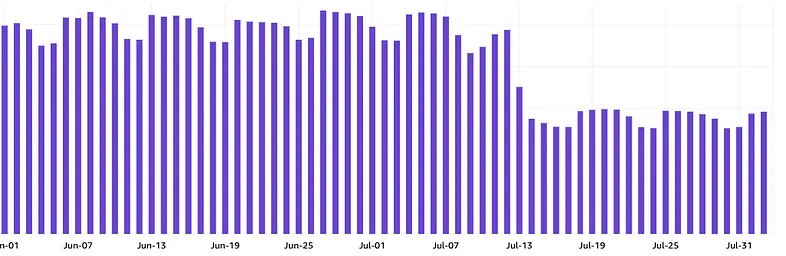
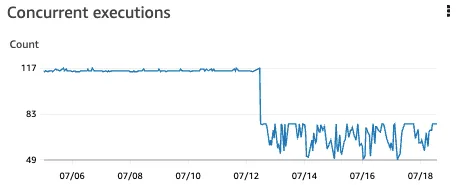
The number of simultaneous executions of Lambda functions decreased. This was primarily caused by reducing the parallelization factor and adjusting the Maximum Batching Window settings. However, this graph doesn't have a significant impact on performance.
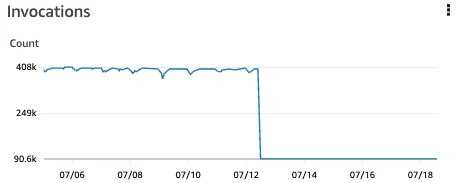
The number of invocations of Lambda functions decreased. This was also a result of reducing the parallelization factor and adjusting the Maximum Batching Window settings. However, this graph doesn't have a significant impact on performance.
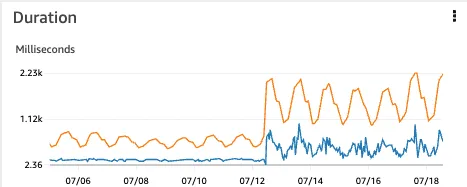
The duration of each invocation increased. Normally, this would be seen as undesirable, but in this case, it was a trade-off to achieve cost reduction. Although it slowed down the ingestion time, it still complied with our service level agreement (SLA), so we proceeded with it. (The blue line represents the minimum duration, and the orange line represents the average duration for each minute.)
 center
center
The iterator age remained unchanged. This means that the Lambda function was fast enough to handle data ingestion. (The spike in the middle of the graph is unrelated to the changes we made in this context.)
Thanks for reading. Feel free to leave a comment in my guestbook.